Rise AI Architecture Platform
From Specification to Technology-Aware, PPA-Optimized RTL.
Every Step Grounded in Hardware Knowledge and Measured by Fast, Accurate Silicon Design Tools
Rise AI Architectural Platform is the industry’s first deterministic Native-AI architecture that transforms structured specifications and algorithms into technology-aware RTL with a matching verification environment, and an executable specification for HW/SW and system-level design. Every AI proposal is evaluated and grounded by the Rise tool chain, which delivers RTL synthesis correlated timing, area, and power in a fraction of the time of other tools. This gives the AI closed loop the speed and accuracy it needs to make real engineering decisions.
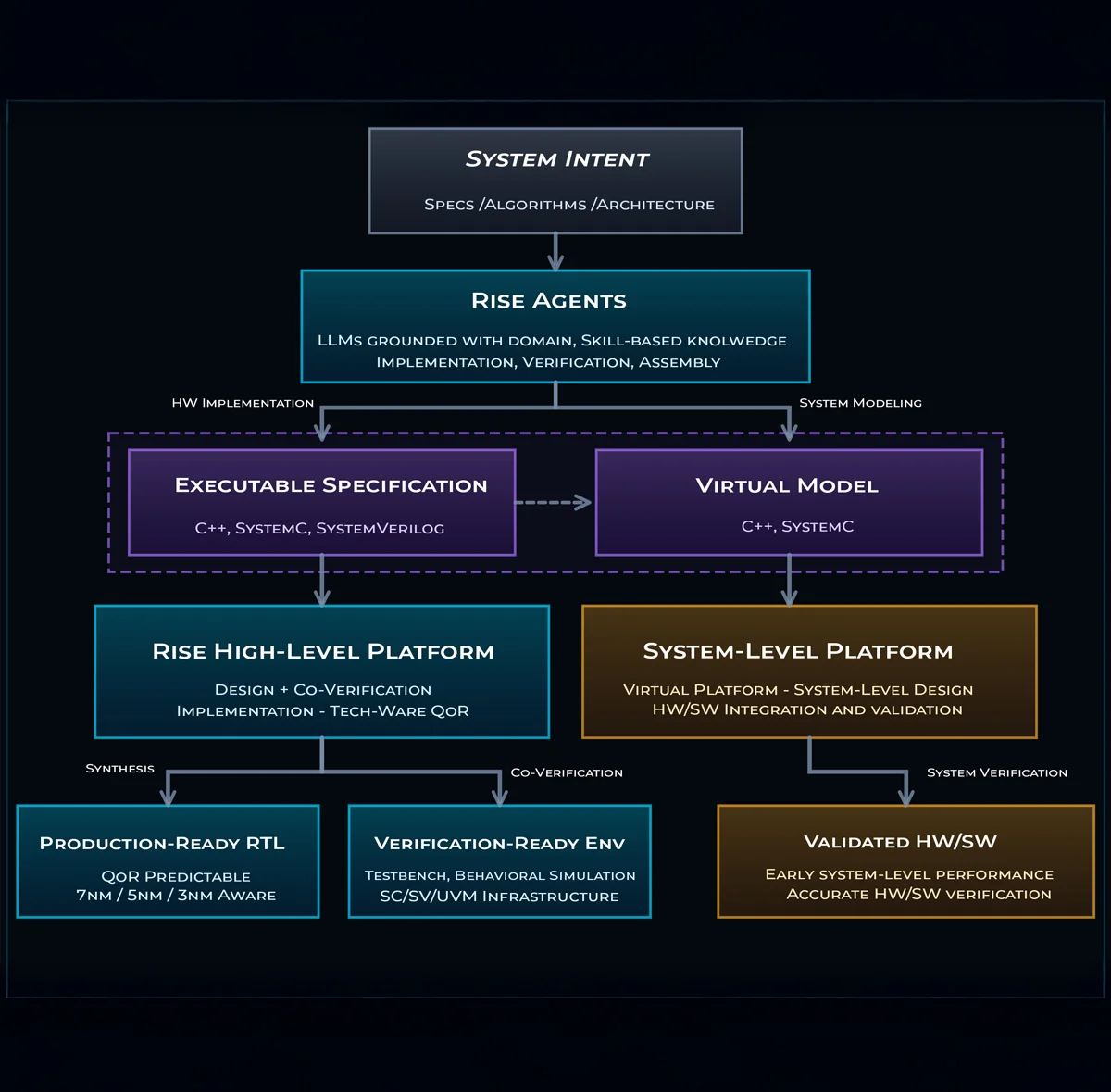
Key Benefits of the Executable Specification
Rise delivers PPA-optimized, verified RTL with dramatically higher productivity than traditional design flows, but it is the executable specification in the flow that shifts left the entire design cycle and enables teams to find and fix problems earlier and faster. As shown below, this single source of truth for hardware functionality and behavior delivers five key benefits that significantly reduce costs, time, and errors across the entire design cycle.

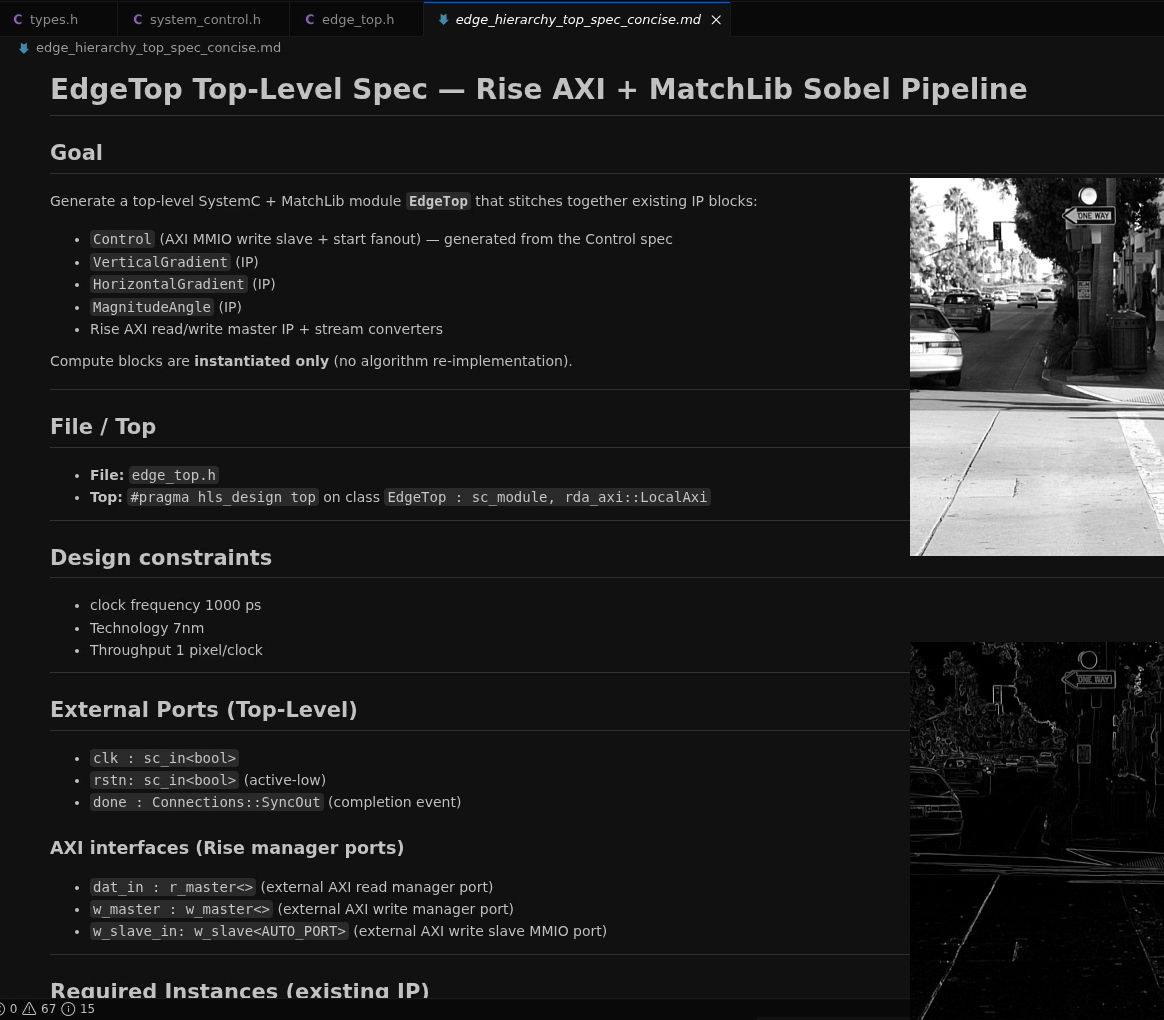
From Structured Intent to Executable Specification
The Rise AI Architectural Platform accepts system intent in any format, whether a spec document, an algorithm, or existing HL design code. The specification does not need to be pin-level precise, what matters is clear hierarchy across purpose, interfaces, data types, and behavioral intent. Users can start with a minimal specification and add detail incrementally.
From this input, Rise AI generates an executable specification in C++, SystemC, or SystemVerilog. Rise has also developed IP and domain expertise tailored for key industry verticals including compute, AI acceleration, image processing, and signal processing, significantly accelerating design generation for these workloads. Users can also create their own AI skills to make Rise AI aware of their proprietary IP and design methodology, extending the platform with institutional knowledge unique to their organization.
Once the executable specification is optimized, the Rise High-Level Platform takes it through synthesis to deliver PPA-optimized RTL and a matching verification environment, correlated to within 10% of production RTL synthesis tools. Learn more about the Rise High-Level Platform
What Makes Rise AI Different From Every Other Approach
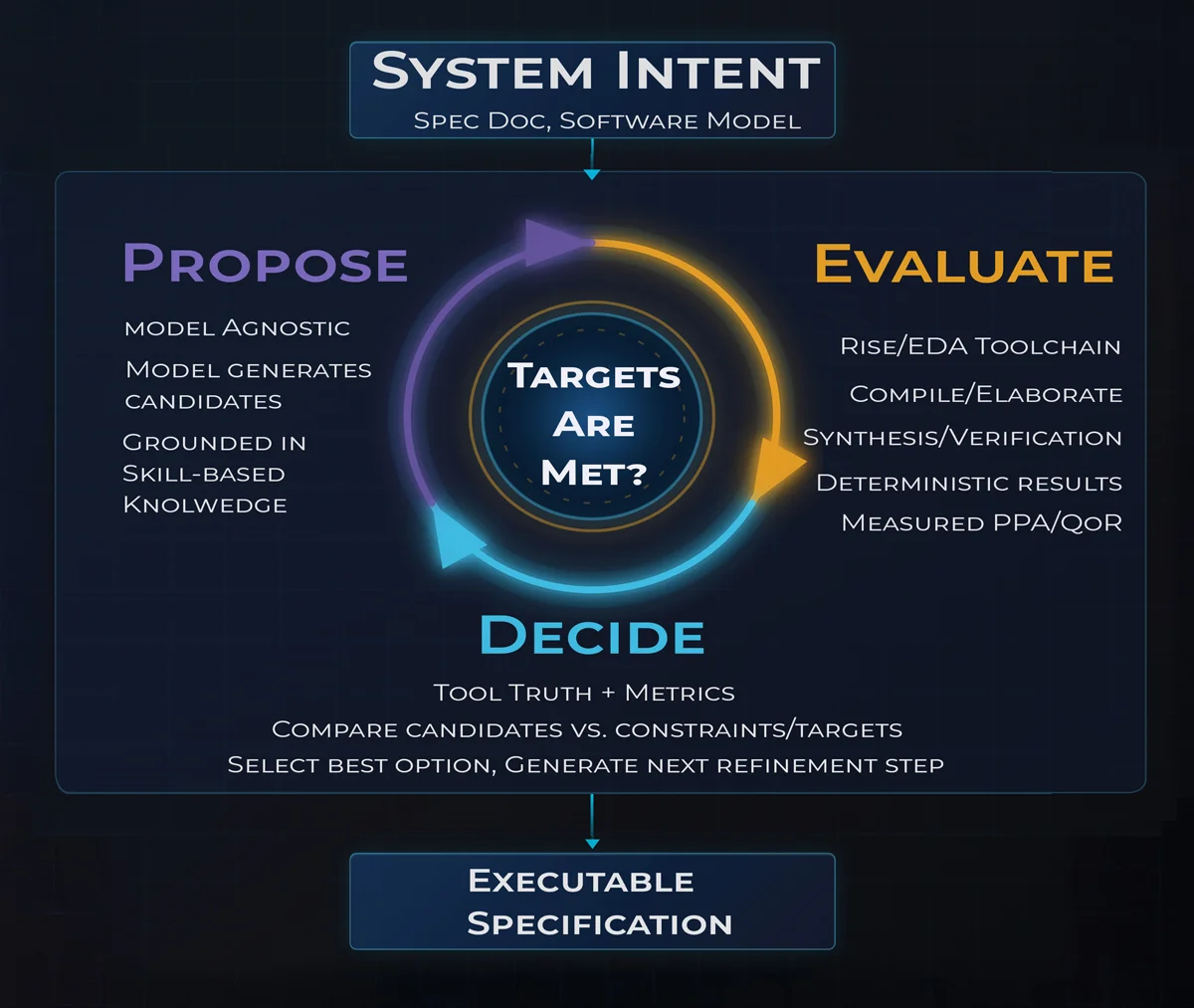
The Propose, Evaluate, Decide Closed Loop
Tool Truth Drives Every Decision
LLMs excel at high-level languages, specifications, and architectural intent, but they are not built to create technology-aware RTL. High-quality RTL training data is extremely limited, LLMs cannot reason about timing, area, power, latency, or throughput, and their outputs are inherently unpredictable in a domain where silicon requires determinism. Attempting to generate RTL directly from an LLM introduces hallucination risk.
Rise solves this by having AI operate at the high-level abstraction where LLMs actually work well, then uses the Rise toolchain to produce RTL with real power, performance, and area metrics. The loop is extremely fast and self-healing. When results come back, the AI reads the structured tool diagnostics, applies a targeted fix scoped only to what failed, and re-runs, using measured PPA feedback to guide the next solution without restarting the full pipeline.
This architecture is why Rise delivers results that are deterministic, verifiable, and directly implementable. Every output traces back to real tool measurements.
The Knowledge Skillset
The Rise Agents Knowledge Skillset — Agents That Understand Hardware, Not Just Code
What makes the Rise AI Platform uniquely capable is its library of purpose-built AI skills, each grounded in a curated hardware knowledge base. The Rise skills and knowledge are built from multi-level coding standards and IP libraries, QoR understanding, domain-specialized IP, multi-level design and verification processes, and Rise documentation and libraries. These skills give each AI agent the hardware expertise it needs to make informed design decisions at every step of the flow.
Rise is model agnostic, supporting any modern Language Model harness, whether frontier foundation models or internal enterprise models, and as new and more capable models emerge they can be integrated easily into the Rise AI Platform.
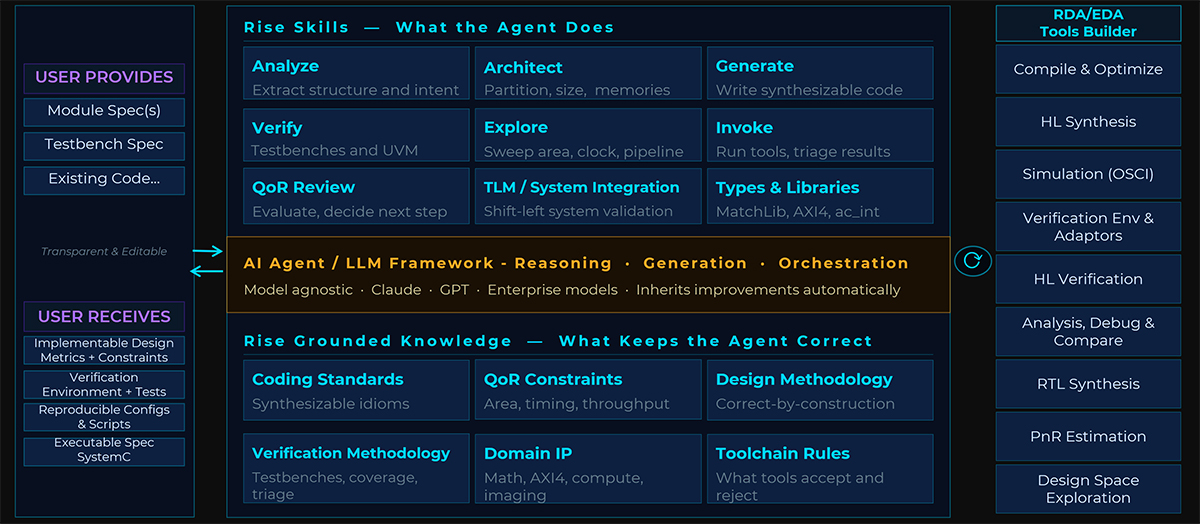
AI Orchestration
A Coordinated, Closed-Loop AI System That Knows How to Fix Itself
The Rise AI Platform coordinates the full workflow across multiple layers working in concert. At the top level, the system manages the end-to-end flow across module and testbench generation, simulation and verification, and design space exploration. Independent modules are architected, built, and synthesized concurrently, significantly accelerating the overall design flow.
What makes Rise AI orchestration genuinely different from other approaches is what happens when something fails. Other AI systems report a failure back to the language model and leave the language model to interpret raw log output and guess at a fix. Rise deterministic tools are truly AI-Native. They analyze every failure and provide the AI with precise, actionable instructions on what to fix and how. The AI applies a targeted fix scoped only to the step that failed and re-runs, without restarting the full pipeline or requiring any human intervention. The result is a self-healing system that converges on a solution quickly and reliably.
Everything that comes out is transparent and editable, giving users full visibility into every step of the process. Users can inspect, modify, and build on the outputs at any point, and reproducible configurations and scripts accompany every result so teams can verify and repeat the process with confidence.


Architected for Flexibility
Designed to Fit Into Your Environment and Grow With Your Needs
Rise AI is designed to fit into existing engineering environments without disruption. The system is Language Model harness-agnostic, integrating across common front-ends and running the same way whether deployed on GitHub, Cursor, or cloud infrastructure. There is no lock-in to a specific toolchain front-end or workflow.
AI-Guided Design Space Exploration
Find the Best Architecture and Know it is Implementable

Every hardware design contains architectural decisions that profoundly affect the final product’s power, performance, and area. Most teams make these decisions early with limited data, and live with the consequences through tapeout. Evaluating architectural alternatives at RTL can take hours if not days per iteration, making meaningful exploration impractical on real project schedules. Rise changes this by running the closed loop at the high level where synthesis completes in seconds, enabling teams to generate and evaluate tens to hundreds of design candidates with correlated PPA feedback before committing to an architecture.
The Rise Optimization Agent uses algorithmic parameter search and learned predictions to converge toward an optimal Pareto front across any combination of metrics including pipeline depth, memory hierarchy, parallelism, area, latency, power, and timing closure. Rather than manual parameter sweeps, the system runs targeted trials and refines based on user-set goals and constraints, with full analysis, debug, and compare visibility at every step.
The flow is designed to be extended with higher fidelity estimation as needed. In one example, Rise integrated with hls4ml to take ML models directly from Keras, TensorFlow, or PyTorch through the full synthesis and verification loop, with the Optimization Agent managing Pareto front analysis across the parameter space. In another, Rise integrated OpenROAD as a plug-in PnR estimation phase, adding physical implementation correlation to the exploration loop and giving teams confidence that the architectures they are selecting will close in silicon.
See a 5-Minute Demo Using a Sobel Edge Detection Algorithm
Watch how the Rise Agentic system take a structured design specification, generate a synthesizable executable specification, and drive it through the closed loop to produce validated, production-quality RTL, transparently and with full visibility at every step.